Apache Lucene is a de facto open source library targeting search and search- related tasks such as indexing or querying.
1. How Lucene indexes documents algorithmically
Lucene uses the inverted index data structure to index documents. The indexing strategy of Lucene is different from others when it creates segments and merges them, rather than uses a single index. Typically, an index segment consists of a dictionary index, a term dictionary and a posting dictionary.
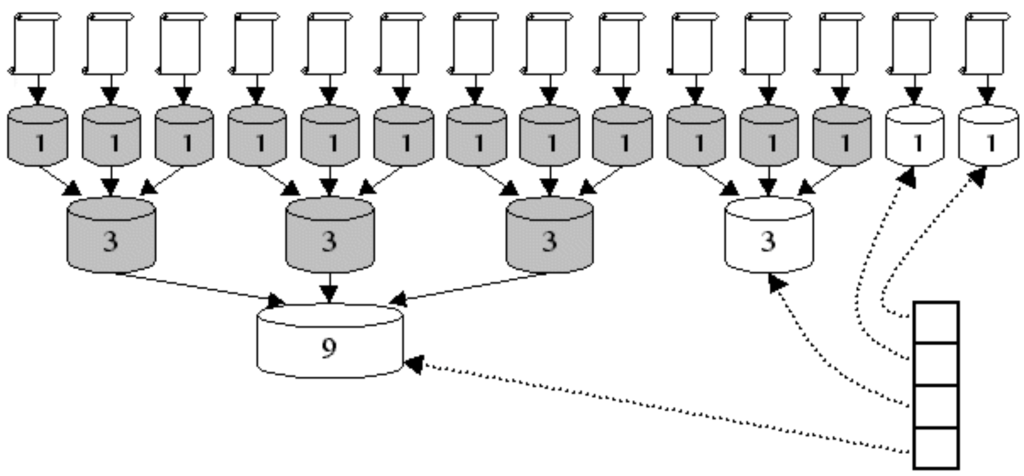
The index diagram with the merge factor b is 3
Figure 1 illustrates an example of an index, where the merge factor equals three. In the example, there are 14 documents in the collection. Lucene repeatedly creates a segment for a document and periodically merges a group of 3 documents. The process is similar when Lucene keeps merging a group of 3 segments until there is no more segment to merge. After merging, all greyed segments will be removed and in total, Lucene merged 5 times after the indexing finishes. The approach of merging and deleting segments is considerably useful as the document collection does not change frequently. More importantly, the segment will never be modified. Instead, Lucene creates new segments when the document collection changes and later, it merges segments into new ones and deletes the old segments. This strategy ensures there is no conflict between reading writing indexes. Furthermore, this strategy also allows Lucene to avoid complex B-trees to store segments. Instead, all segments will be stored in flat files.
2. Extract text and index
Typically we can divide indexing documents into two distinct procedures, extracting text and creating index (Figure 2).
![Figure 2. Indexing with Lucene breaks down into three main operations: extracting text from source documents, analyzing it, and saving it to the index [Photo courtesy of Lucene in Action]](/images/analyze-lucene.png)
Figure 2. Indexing with Lucene breaks down into three main operations: extracting text from source documents, analyzing it, and saving it to the index [Photo courtesy of Lucene in Action]
In extracting procedure, it is common to use a versatile parser that can extract textual contents from documents. One of widely known tools we can use to parse documents is Apache Tika. When parsing completes, we will have an input stream that needs to be indexed. It is the second procedure of our index process – creating an index.
More often than not, we do not index everything we retrieve from the input stream. We instead need to apply analysis process where we will discard unimportant terms from the textual content (e.g., punctuations, stopping words). In Lucene, the analysis process is handled by Analyzer. The framework already provides handy and powerful analysers that we can use without customising in a majority of problems.
After analysing, the textual contents are ready to be indexed.
3. Building an index
In this section, we will look at how we can create a new index and add documents to it.
3.1 Construct an index writer
In Lucene, the index is created and maintained by IndexWriter. The IndexWriter constructors can be defined in various ways but most often we simply need to supply
Directory dwhere the index will be storedIndexWriterConfig confholds all the configuration that is used to construct anIndexWriter
In the code below, we can see that I have define an instance of IndexWriterConfig with a specialised Analyzer`. The purpose is I want to analyse documents in a particular way that suits my personal needs (e.g., I want to keep specific words that built-in analysers will certainly remove).
In the given code sample, we use FSDirectory . There are other alternative solutions, such as SimpleFSDirectory , NIOFSDirectory .
/**
* Create an Indexer using the given directory to store index files, and the
* directory need to be indexed.
*
* */
public Indexer(String anIndexDir, String aDataDir) {
// set place to store indexes
this.indexDir = anIndexDir;
// set directory has to be indexed
this.dataDir = aDataDir;
try {
// create Directory to store indexes, use FSDirectory.open
// to automatically pick the most suitable directory implementation
Directory dir = FSDirectory.open(new File(indexDir));
// create an instance of Analyzer with my own custom analyzer
analyzer = new MyCustomAnalyzer();
// create configuration for new IndexWriter
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_46,
analyzer);
// create IndexWriter, which can create new index, or
// adds, removes, or updates documents in the index
// however, it can not read or search
this.writer = new IndexWriter(dir, conf);
} catch (IOException e) {
e.printStackTrace();
}
}
3.2 Modelling document
In the framework textual content is modelled using the class Document . This class allows to model a document instance with numerous attributes where for every attribute we can also define using the class Field .
In the sample code below, I have define an Document instance with a number of attributes:
- Document ID: because in practice we may have thousands of documents, I have used base64 to generate unique IDs for documents. Notice that we supply the
StringFieldconstructor with the variableField.Store.YES, which means the values of this attributes will be stored in index files. More importantly, we do not index theStringFieldby default. - File path: will be stored
- Content field: as you may think, we need to index the content field for further full-text search. However, we may or may not store it in the index files. It is a matter of choice. In this particular case, I choose to store the field.
Document doc = new Document();
// docId
// generated by base64 of filepath
String id = BaseEncoding.base64().encode(f.getCanonicalPath().getBytes(Charsets.US_ASCII));
doc.add(new StringField(MyDocumentIndexedProperties.ID_FIELD, id,
Field.Store.YES));
// filepath
doc.add(new StringField(MyDocumentIndexedProperties.FILE_PATH_FIELD, f
.getCanonicalPath(), Field.Store.YES));
// content field
TokenStream ts = analyzer.tokenStream(
MyDocumentIndexedProperties.CONTENT_FIELD, new StringReader(
handler.toString()));
Field contentField = new Field(
MyDocumentIndexedProperties.CONTENT_FIELD,
AnalyzerUtils.tokenStreamToString(ts), TYPE_STORED);
ts.close();
doc.add(contentField);
3.3 Index document
While Lucene consists many components, it, at the same time, uses such extremely simple and intuitive methods to abstract the complex structures that it is fascinating seeing how it is simple to perform indexing.
Document doc = new Document();
//modelling document in the same manner as section 3.2
//...
//...
//add document to the index
writer.addDocument(doc);
//close the index when finish
//which also means we commit the index to be ready to store
writer.close()
4. Full-text search
Until now we have an index that can be used to search over. To initialise a search, we must input a search query, which can be a keyword or even a wild card. In Lucene, the search query will firstly be handled by QueryParser where the query will be parsed into meaningful structure, called Query . After that, the IndexSearcher will consume Query instance in order to look up over the index.
// searcher
IndexSearcher searcher = new IndexSearcher(this.indexReader);
// query parser
QueryParser parser = new QueryParser(Version.LUCENE_46, "content", new SimpleAnalyzer());
// parsing query
Query q = parser.parse("....");
// look up and return top 10 relevant documents
Topdocs docs = searcher.search(query, 10);
5. Bottom line
So far we have seen a “hello world” example of using Lucene to perform full-text search. In real project, we can expect there are a number of possibilities where we need to tweak Lucene so that it can serve our search purpose at a higher level. An example scenario is when we need to support like-this search where the system allows the user to search textual contents that are similar to the keywords. Theoretically we can measure the similarity by using distance measure methods, such as Euclidean distance measure, cosine distance measure, or Manhattan distance measure, etc. Another scenario is when we can create a system that supports synonym search where we retrieve not only document contains the search keywords but also documents that has synonyms of keywords.
As said, in spite of the simplicity, Lucene adds a tremendous amount of support in building a powerful search tool. In the future post, I may discuss how we can combine both Apache Lucene and Apache Mahout (a machine learning framework) in order to index a corpus and use that index to perform clustering. Stay tuned!