In Part 2 of this series, we have seen that with LeNet-5, we can only achieve about 68% of accuracy on the test set of CIFAR-10. LeNet-5 is kinda a rudimentary when its total trainable params is only about 62,5k, which means that its capability to learn a dataset such as CIFAR-10 is quite limited. Remember that LeNet-5 is proposed by Yann LeCun in 1988 to only recognize handwritten characters in gray scale, while CIFAR-10 is much more complex (than MNIST) because they are images with 3 channels, RGB. The complexity of CIFAR-10 thus requires more sophisticated DL architectures.
In this post, we proceed to use a deeper ConvNet named VGG16 and see how it handles CIFAR10 dataset.
I - Load Packages & Preprocess Data
from tensorflow import keras
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Input, \
Flatten, Activation, BatchNormalization, Dropout
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.regularizers import l2
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Set seed
np.random.seed(123)
# Constants
NUMBER_OF_CLASSES = 10
EPOCHS = 150
INITIAL_LR = 1e-2
IMG_SHAPE = (32, 32, 3)
BATCH_SIZE = 32
1. Load data
(X_train, Y_train), (X_test, Y_test) = keras.datasets.cifar10.load_data()
X_train = X_train / 255
X_test = X_test / 255
Y_train = keras.utils.to_categorical(Y_train, NUMBER_OF_CLASSES)
Y_test = keras.utils.to_categorical(Y_test, NUMBER_OF_CLASSES)
2. Preprocessing data
# Global contrast normalization preprocessing
def global_contrast_normalization(X, s=1, lmda=10, epsilon=0.000000001):
X_average = np.mean(X)
X = X - X_average
contrast = np.sqrt(lmda + np.mean(X**2))
X = s * X / max(contrast, epsilon)
return X
kwargs_datagen = dict(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
zca_whitening=True,
validation_split=0.2,
preprocessing_function=global_contrast_normalization)
datagen = ImageDataGenerator(**kwargs_datagen)
datagen.fit(X_train)
train_gen = datagen.flow(X_train, Y_train, subset='training')
val_gen = datagen.flow(X_train, Y_train, subset='validation')
/usr/local/lib/python3.6/dist-packages/keras_preprocessing/image/image_data_generator.py:337: UserWarning: This ImageDataGenerator specifies `zca_whitening`, which overrides setting of `featurewise_center`.
warnings.warn('This ImageDataGenerator specifies '
II - VGG16 Model Training and Validation
1. Model construction
# Input
inputs = Input(shape=IMG_SHAPE)
# Block 1
x = Conv2D(filters=64, kernel_size=(3, 3), strides=1, padding='same')(inputs)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=64, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Dropout(0.25)(x)
# Block 2
x = Conv2D(filters=128, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=128, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Dropout(0.25)(x)
# Block 3
x = Conv2D(filters=256, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=256, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=256, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Dropout(0.25)(x)
# Block 4
x = Conv2D(filters=512, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Dropout(0.25)(x)
# Block 5
x = Conv2D(filters=512, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=1, padding='same')(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = Dropout(0.25)(x)
x = Flatten()(x)
# Dense
x = Dense(units=512, activation='relu', kernel_regularizer=l2(5e-4))(x)
x = Dropout(0.4)(x)
x = Dense(units=256, activation='relu', kernel_regularizer=l2(5e-4))(x)
x = Dropout(0.4)(x)
# Output
outputs = Dense(units=NUMBER_OF_CLASSES, activation='softmax')(x)
vgg16 = keras.Model(inputs=inputs, outputs=outputs)
# Model summary
vgg16.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
activation (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 32, 32, 64) 256
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 64) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
activation_2 (Activation) (None, 16, 16, 128) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 16, 16, 128) 512
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
activation_3 (Activation) (None, 16, 16, 128) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 16, 16, 128) 512
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
activation_4 (Activation) (None, 8, 8, 256) 0
_________________________________________________________________
batch_normalization_4 (Batch (None, 8, 8, 256) 1024
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
activation_5 (Activation) (None, 8, 8, 256) 0
_________________________________________________________________
batch_normalization_5 (Batch (None, 8, 8, 256) 1024
_________________________________________________________________
conv2d_6 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
activation_6 (Activation) (None, 8, 8, 256) 0
_________________________________________________________________
batch_normalization_6 (Batch (None, 8, 8, 256) 1024
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 4, 4, 256) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 512) 1180160
_________________________________________________________________
activation_7 (Activation) (None, 4, 4, 512) 0
_________________________________________________________________
batch_normalization_7 (Batch (None, 4, 4, 512) 2048
_________________________________________________________________
conv2d_8 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
activation_8 (Activation) (None, 4, 4, 512) 0
_________________________________________________________________
batch_normalization_8 (Batch (None, 4, 4, 512) 2048
_________________________________________________________________
conv2d_9 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
activation_9 (Activation) (None, 4, 4, 512) 0
_________________________________________________________________
batch_normalization_9 (Batch (None, 4, 4, 512) 2048
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 2, 2, 512) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 2, 2, 512) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
activation_10 (Activation) (None, 2, 2, 512) 0
_________________________________________________________________
batch_normalization_10 (Batc (None, 2, 2, 512) 2048
_________________________________________________________________
conv2d_11 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
activation_11 (Activation) (None, 2, 2, 512) 0
_________________________________________________________________
batch_normalization_11 (Batc (None, 2, 2, 512) 2048
_________________________________________________________________
conv2d_12 (Conv2D) (None, 2, 2, 512) 2359808
_________________________________________________________________
activation_12 (Activation) (None, 2, 2, 512) 0
_________________________________________________________________
batch_normalization_12 (Batc (None, 2, 2, 512) 2048
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 1, 1, 512) 0
_________________________________________________________________
dropout_4 (Dropout) (None, 1, 1, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 512) 0
_________________________________________________________________
dense (Dense) (None, 512) 262656
_________________________________________________________________
dropout_5 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 131328
_________________________________________________________________
dropout_6 (Dropout) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 15,128,138
Trainable params: 15,119,690
Non-trainable params: 8,448
_________________________________________________________________
2. Model training
# Callbacks
class Learning_Rate_Report(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs=None):
lr = float(keras.backend.get_value(self.model.optimizer.learning_rate))
print("Learning rate: ", lr)
lr_report = Learning_Rate_Report()
early_stopping = EarlyStopping(monitor='val_loss',
min_delta=1e-3,
patience=5)
lr_reduction = ReduceLROnPlateau(monitor='val_loss',
factor=0.5,
patience=3,
min_lr=1e-5)
opt = SGD(learning_rate=INITIAL_LR, momentum=0.9)
vgg16.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['accuracy'])
history = vgg16.fit(train_gen,
validation_data=val_gen,
steps_per_epoch=len(train_gen),
epochs=EPOCHS,
batch_size=BATCH_SIZE,
shuffle=True,
callbacks=[early_stopping, lr_reduction, lr_report])
Epoch 1/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 226s 179ms/step - loss: 2.5525 - accuracy: 0.1954 - val_loss: 2.2503 - val_accuracy: 0.2390 - ETA: 2:01 - loss: 2.9090 - accuracy: 0.1304
Epoch 2/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 228s 182ms/step - loss: 2.1683 - accuracy: 0.2867 - val_loss: 2.0093 - val_accuracy: 0.3485
Epoch 3/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 234s 187ms/step - loss: 1.9580 - accuracy: 0.3589 - val_loss: 1.8452 - val_accuracy: 0.3939
Epoch 4/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 233s 187ms/step - loss: 1.7507 - accuracy: 0.4339 - val_loss: 1.5218 - val_accuracy: 0.5101 - ETA: 1:57 - loss: 1.8109 - accuracy: 0.4119 - ETA: 1:43 - loss: 1.8073 - accuracy: 0.4117 - ETA: 1:21 - loss: 1.7922 - accuracy: 0.4162
Epoch 5/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 231s 185ms/step - loss: 1.5906 - accuracy: 0.4881 - val_loss: 1.4488 - val_accuracy: 0.5390 - ETA: 2:45 - loss: 1.6464 - accuracy: 0.4660 - ETA: 2:06 - loss: 1.6460 - accuracy: 0.4699
Epoch 6/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 221s 177ms/step - loss: 1.4556 - accuracy: 0.5335 - val_loss: 1.2562 - val_accuracy: 0.6037 - ETA: 2:30 - loss: 1.4953 - accuracy: 0.5206
Epoch 7/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 223s 179ms/step - loss: 1.3464 - accuracy: 0.5711 - val_loss: 1.1923 - val_accuracy: 0.6100 - ETA: 2:34 - loss: 1.4094 - accuracy: 0.5523
Epoch 8/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 221s 176ms/step - loss: 1.2569 - accuracy: 0.6004 - val_loss: 1.2348 - val_accuracy: 0.6113
Epoch 9/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 230s 184ms/step - loss: 1.1698 - accuracy: 0.6309 - val_loss: 1.1915 - val_accuracy: 0.6205 - ETA: 2:18 - loss: 1.1952 - accuracy: 0.6211
Epoch 10/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 212s 170ms/step - loss: 1.1113 - accuracy: 0.6454 - val_loss: 0.9383 - val_accuracy: 0.6968
Epoch 11/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 216s 172ms/step - loss: 1.0593 - accuracy: 0.6629 - val_loss: 0.9354 - val_accuracy: 0.6989 - ETA: 1:16 - loss: 1.0620 - accuracy: 0.6615
Epoch 12/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 232s 185ms/step - loss: 1.0107 - accuracy: 0.6781 - val_loss: 1.0306 - val_accuracy: 0.6669 - ETA: 2:36 - loss: 1.0055 - accuracy: 0.6756
Epoch 13/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 244s 195ms/step - loss: 0.9667 - accuracy: 0.6921 - val_loss: 0.8318 - val_accuracy: 0.7337 - ETA: 2:03 - loss: 0.9671 - accuracy: 0.6911 - ETA: 41s - loss: 0.9672 - accuracy: 0.6922
Epoch 14/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 248s 198ms/step - loss: 0.9644 - accuracy: 0.6948 - val_loss: 0.8274 - val_accuracy: 0.7329 - ETA: 1:00 - loss: 0.9650 - accuracy: 0.6954
Epoch 15/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 254s 203ms/step - loss: 0.9502 - accuracy: 0.7005 - val_loss: 0.8798 - val_accuracy: 0.7204 - ETA: 1:07 - loss: 0.9549 - accuracy: 0.7000
Epoch 16/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 255s 204ms/step - loss: 0.9053 - accuracy: 0.7182 - val_loss: 0.9334 - val_accuracy: 0.7153 - ETA: 2:17 - loss: 0.9080 - accuracy: 0.7178
Epoch 17/150
Learning rate: 0.009999999776482582
1250/1250 [==============================] - 239s 191ms/step - loss: 0.8667 - accuracy: 0.7288 - val_loss: 0.8433 - val_accuracy: 0.7327 - ETA: 1:35 - loss: 0.8675 - accuracy: 0.7292
Epoch 18/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 247s 197ms/step - loss: 0.7847 - accuracy: 0.7534 - val_loss: 0.6658 - val_accuracy: 0.7879 - ETA: 2:46 - loss: 0.7831 - accuracy: 0.7487 - ETA: 56s - loss: 0.7952 - accuracy: 0.7483 - ETA: 7s - loss: 0.7840 - accuracy: 0.7528
Epoch 19/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 246s 197ms/step - loss: 0.7416 - accuracy: 0.7687 - val_loss: 0.6679 - val_accuracy: 0.7833 - ETA: 2:50 - loss: 0.7231 - accuracy: 0.7739
Epoch 20/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 237s 190ms/step - loss: 0.7377 - accuracy: 0.7681 - val_loss: 0.8575 - val_accuracy: 0.7348 - ETA: 44s - loss: 0.7398 - accuracy: 0.7670
Epoch 21/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 251s 201ms/step - loss: 0.7044 - accuracy: 0.7772 - val_loss: 0.6181 - val_accuracy: 0.8006 - ETA: 1:19 - loss: 0.6998 - accuracy: 0.7770
Epoch 22/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 245s 196ms/step - loss: 0.6906 - accuracy: 0.7826 - val_loss: 0.6199 - val_accuracy: 0.8030
Epoch 23/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 256s 204ms/step - loss: 0.6758 - accuracy: 0.7873 - val_loss: 0.6086 - val_accuracy: 0.8085
Epoch 24/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 257s 205ms/step - loss: 0.6586 - accuracy: 0.7920 - val_loss: 0.5950 - val_accuracy: 0.8097 - ETA: 3:17 - loss: 0.6843 - accuracy: 0.7903
Epoch 25/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 263s 211ms/step - loss: 0.6507 - accuracy: 0.7950 - val_loss: 0.5860 - val_accuracy: 0.8110 - ETA: 2:20 - loss: 0.6449 - accuracy: 0.7969 - ETA: 1:42 - loss: 0.6431 - accuracy: 0.7976
Epoch 26/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 263s 210ms/step - loss: 0.6290 - accuracy: 0.8026 - val_loss: 0.5762 - val_accuracy: 0.8154 - ETA: 1:29 - loss: 0.6306 - accuracy: 0.8015
Epoch 27/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 258s 207ms/step - loss: 0.6198 - accuracy: 0.8049 - val_loss: 0.5733 - val_accuracy: 0.8121 - ETA: 2:05 - loss: 0.6220 - accuracy: 0.8049
Epoch 28/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 262s 210ms/step - loss: 0.6003 - accuracy: 0.8101 - val_loss: 0.5566 - val_accuracy: 0.8202
Epoch 29/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 255s 204ms/step - loss: 0.5934 - accuracy: 0.8101 - val_loss: 0.5566 - val_accuracy: 0.8205 - ETA: 1:14 - loss: 0.5892 - accuracy: 0.8120 - ETA: 1:04 - loss: 0.5914 - accuracy: 0.8105
Epoch 30/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 247s 198ms/step - loss: 0.5737 - accuracy: 0.8181 - val_loss: 0.5429 - val_accuracy: 0.8286 - ETA: 2:27 - loss: 0.5775 - accuracy: 0.8148 - ETA: 1:56 - loss: 0.5739 - accuracy: 0.8166 - ETA: 25s - loss: 0.5747 - accuracy: 0.8170 - ETA: 18s - loss: 0.5754 - accuracy: 0.8169
Epoch 31/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 252s 202ms/step - loss: 0.5647 - accuracy: 0.8202 - val_loss: 0.5278 - val_accuracy: 0.8355 - ETA: 2:15 - loss: 0.5699 - accuracy: 0.8182 - ETA: 20s - loss: 0.5660 - accuracy: 0.8194
Epoch 32/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 253s 202ms/step - loss: 0.5504 - accuracy: 0.8263 - val_loss: 0.5393 - val_accuracy: 0.8310 - ETA: 2:33 - loss: 0.5433 - accuracy: 0.8280
Epoch 33/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 247s 197ms/step - loss: 0.5508 - accuracy: 0.8255 - val_loss: 0.5288 - val_accuracy: 0.8334 - ETA: 28s - loss: 0.5501 - accuracy: 0.8261
Epoch 34/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 257s 205ms/step - loss: 0.5405 - accuracy: 0.8287 - val_loss: 0.5154 - val_accuracy: 0.8352 - ETA: 1:53 - loss: 0.5401 - accuracy: 0.8301 - ETA: 31s - loss: 0.5423 - accuracy: 0.8278 - ETA: 18s - loss: 0.5413 - accuracy: 0.8283
Epoch 35/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 272s 217ms/step - loss: 0.5269 - accuracy: 0.8323 - val_loss: 0.5030 - val_accuracy: 0.8350 - ETA: 2:19 - loss: 0.5193 - accuracy: 0.8315 - ETA: 1:30 - loss: 0.5269 - accuracy: 0.8321 - ETA: 1:03 - loss: 0.5271 - accuracy: 0.8318
Epoch 36/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 271s 217ms/step - loss: 0.5232 - accuracy: 0.8340 - val_loss: 0.5244 - val_accuracy: 0.8363
Epoch 37/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 263s 211ms/step - loss: 0.5137 - accuracy: 0.8389 - val_loss: 0.5242 - val_accuracy: 0.8341 - ETA: 1:37 - loss: 0.5189 - accuracy: 0.8398
Epoch 38/150
Learning rate: 0.004999999888241291
1250/1250 [==============================] - 259s 207ms/step - loss: 0.5109 - accuracy: 0.8400 - val_loss: 0.5044 - val_accuracy: 0.8365 - ETA: 2:45 - loss: 0.5048 - accuracy: 0.8389
Epoch 39/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 264s 211ms/step - loss: 0.4720 - accuracy: 0.8515 - val_loss: 0.4563 - val_accuracy: 0.8543 - ETA: 2:49 - loss: 0.4740 - accuracy: 0.8531 - ETA: 2:39 - loss: 0.4759 - accuracy: 0.8528
Epoch 40/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 262s 210ms/step - loss: 0.4577 - accuracy: 0.8545 - val_loss: 0.4588 - val_accuracy: 0.8545 - ETA: 1:26 - loss: 0.4585 - accuracy: 0.8538 - ETA: 1:10 - loss: 0.4568 - accuracy: 0.8546 - ETA: 26s - loss: 0.4565 - accuracy: 0.8552
Epoch 41/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 266s 213ms/step - loss: 0.4542 - accuracy: 0.8563 - val_loss: 0.4525 - val_accuracy: 0.8549 - ETA: 3:12 - loss: 0.4460 - accuracy: 0.8610 - ETA: 2:59 - loss: 0.4520 - accuracy: 0.8575 - ETA: 2:58 - loss: 0.4543 - accuracy: 0.8564 - ETA: 2:24 - loss: 0.4526 - accuracy: 0.8561 - ETA: 2:22 - loss: 0.4536 - accuracy: 0.8559 - ETA: 1:59 - loss: 0.4540 - accuracy: 0.8564
Epoch 42/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 260s 208ms/step - loss: 0.4401 - accuracy: 0.8589 - val_loss: 0.4455 - val_accuracy: 0.8544 - ETA: 9s - loss: 0.4402 - accuracy: 0.8592
Epoch 43/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 275s 220ms/step - loss: 0.4360 - accuracy: 0.8590 - val_loss: 0.4508 - val_accuracy: 0.8520 - ETA: 3:07 - loss: 0.4195 - accuracy: 0.8659 - ETA: 2s - loss: 0.4362 - accuracy: 0.8589
Epoch 44/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 269s 215ms/step - loss: 0.4312 - accuracy: 0.8619 - val_loss: 0.4377 - val_accuracy: 0.8564 - ETA: 2:51 - loss: 0.4263 - accuracy: 0.8630 - ETA: 2:21 - loss: 0.4305 - accuracy: 0.8640
Epoch 45/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 264s 211ms/step - loss: 0.4224 - accuracy: 0.8655 - val_loss: 0.4470 - val_accuracy: 0.8569 - ETA: 3:01 - loss: 0.4082 - accuracy: 0.8688 - ETA: 2:57 - loss: 0.4045 - accuracy: 0.8705 - ETA: 2:19 - loss: 0.4204 - accuracy: 0.8673
Epoch 46/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 262s 209ms/step - loss: 0.4166 - accuracy: 0.8640 - val_loss: 0.4441 - val_accuracy: 0.8620 - ETA: 2:36 - loss: 0.4236 - accuracy: 0.8622 - ETA: 2:19 - loss: 0.4216 - accuracy: 0.8633 - ETA: 1:58 - loss: 0.4142 - accuracy: 0.8653 - ETA: 1:45 - loss: 0.4167 - accuracy: 0.8640 - ETA: 54s - loss: 0.4158 - accuracy: 0.8640 - ETA: 10s - loss: 0.4165 - accuracy: 0.8640
Epoch 47/150
Learning rate: 0.0024999999441206455
1250/1250 [==============================] - 269s 216ms/step - loss: 0.4113 - accuracy: 0.8684 - val_loss: 0.4395 - val_accuracy: 0.8560 - ETA: 2:10 - loss: 0.4089 - accuracy: 0.8689 - ETA: 14s - loss: 0.4115 - accuracy: 0.8686 - ETA: 0s - loss: 0.4112 - accuracy: 0.8685
Epoch 48/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 264s 211ms/step - loss: 0.3929 - accuracy: 0.8736 - val_loss: 0.4264 - val_accuracy: 0.8621 - ETA: 3:19 - loss: 0.4117 - accuracy: 0.8700
Epoch 49/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 230s 184ms/step - loss: 0.3883 - accuracy: 0.8737 - val_loss: 0.4260 - val_accuracy: 0.8626
Epoch 50/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 236s 189ms/step - loss: 0.3857 - accuracy: 0.8762 - val_loss: 0.4286 - val_accuracy: 0.8631 - ETA: 27s - loss: 0.3822 - accuracy: 0.8772
Epoch 51/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 233s 186ms/step - loss: 0.3808 - accuracy: 0.8771 - val_loss: 0.4195 - val_accuracy: 0.8634
Epoch 52/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 235s 188ms/step - loss: 0.3847 - accuracy: 0.8741 - val_loss: 0.4181 - val_accuracy: 0.8665
Epoch 53/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 242s 193ms/step - loss: 0.3704 - accuracy: 0.8793 - val_loss: 0.4171 - val_accuracy: 0.8659
Epoch 54/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 245s 196ms/step - loss: 0.3692 - accuracy: 0.8806 - val_loss: 0.4130 - val_accuracy: 0.8687 - ETA: 16s - loss: 0.3683 - accuracy: 0.8809
Epoch 55/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 251s 201ms/step - loss: 0.3693 - accuracy: 0.8796 - val_loss: 0.4015 - val_accuracy: 0.8722
Epoch 56/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 262s 209ms/step - loss: 0.3703 - accuracy: 0.8798 - val_loss: 0.4111 - val_accuracy: 0.8689 - ETA: 1:52 - loss: 0.3672 - accuracy: 0.8799 - ETA: 1:24 - loss: 0.3671 - accuracy: 0.8799 - ETA: 38s - loss: 0.3675 - accuracy: 0.8802
Epoch 57/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 263s 210ms/step - loss: 0.3650 - accuracy: 0.8820 - val_loss: 0.4050 - val_accuracy: 0.8648 - ETA: 1:38 - loss: 0.3713 - accuracy: 0.8794
Epoch 58/150
Learning rate: 0.0012499999720603228
1250/1250 [==============================] - 255s 204ms/step - loss: 0.3643 - accuracy: 0.8826 - val_loss: 0.4177 - val_accuracy: 0.8646 Epoch 59/150
Learning rate: 0.0006249999860301614
1250/1250 [==============================] - 239s 191ms/step - loss: 0.3567 - accuracy: 0.8834 - val_loss: 0.4052 - val_accuracy: 0.8681
Epoch 60/150
Learning rate: 0.0006249999860301614
1250/1250 [==============================] - 222s 177ms/step - loss: 0.3477 - accuracy: 0.8867 - val_loss: 0.4007 - val_accuracy: 0.8686 ### 3. Test
# Test
test_datagen = ImageDataGenerator(zca_whitening=True,
preprocessing_function=global_contrast_normalization)
test_datagen.fit(X_train)
test_gen = test_datagen.flow(X_test, Y_test)
vgg16.evaluate(test_gen)
313/313 [==============================] - 32s 102ms/step - loss: 0.4285 - accuracy: 0.8684
[0.42849862575531006, 0.868399977684021]
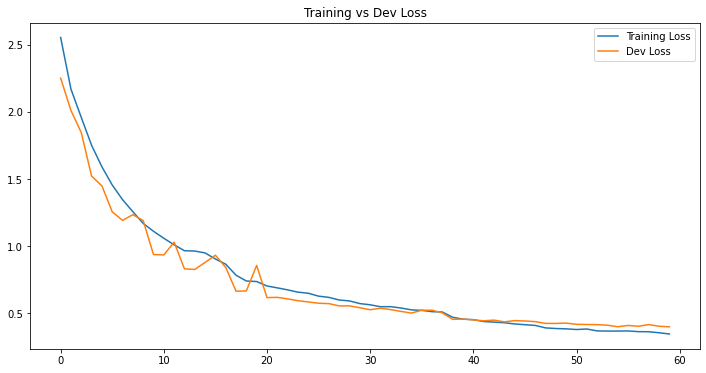
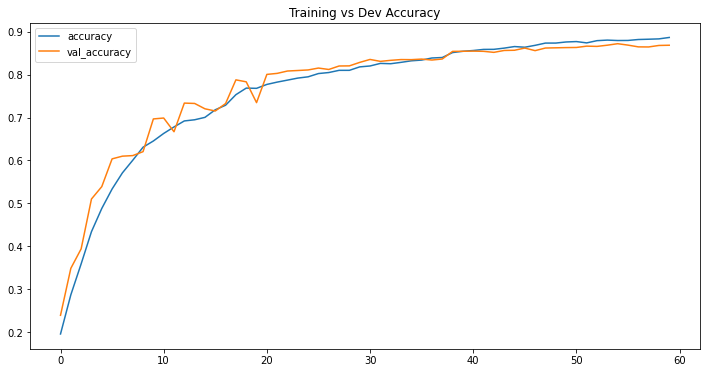
III - Model History
df_loss_acc = pd.DataFrame(history.history)
df_loss_acc.describe()
# Plot history
df_loss = df_loss_acc[['loss', 'val_loss']]
df_loss = df_loss.rename(columns={'loss': 'Training Loss', 'val_loss': 'Dev Loss'})
df_acc = df_loss_acc[['accuracy', 'val_accuracy']]
df_acc = df_acc.rename(columns={'acc': 'Training Accuracy', 'val_acc': 'Dev Accuracy'})
df_loss.plot(title="Training vs Dev Loss", figsize=(12, 6))
df_acc.plot(title="Training vs Dev Accuracy", figsize=(12, 6))
plt.show()
IV - Conclusion
In this post, we have seen that with little to no tuning, VGG16 can achieve 86% on the the test set. The training and validation figures show that there was no noticeable overfitting in our model, which is a good sign. And remember that since we used 30k for training, 20k for validation and 10k for test, it is highly possible that we can achieve much higher performance if we retrain the whole model with total 50k images.